
经典15年i春秋渗透测试系统化教程-课时2-HTTP请求与响应-学习笔记
第3章 Web 应用程序技术
Web 应用程序使用各种不同的技术实现其功能。本章简要介绍渗透测试员在攻击 Web 应用程序时可能遇到的关键技术。我们将分析HTTP协议、服务器和客户端常用的技术以及用于在各种情形下呈现数据的编码方案。这些技术大都简单易懂,掌握其相关特性对于向Web应用程序发动有效攻击极其重要。
3.1 HTTP
HTTP(HyperText Transfer Protocol,超文本传输协议)是访问万维网使用的核心通信协议,也是今天所有Web应用程序使用的通信协议。最初,HTTP只是一个为获取基于文本的静态资源而开发的简单协议,后来人们以各种形式扩展和利用它,使其能够支持如今常见的复杂分布式应用程序。
HTTP 使用一种基于消息的模型:客户端送出一条请求消息,而后由服务器返回一条响应消息。该协议基本上不需要连接,虽然HTTP使用有状态的TCP协议作为它的传输机制,但每次请求与响应交换都自动完成,并且可能使用不同的TCP连接。
补充:静态网页和动态网页
网页可分为静态网页与动态网页两种形式。在介绍这两种网页之前,我们先来了解一下网络构成中的服务器(Server)与客户机(Client)。
服务器是安装有服务器软件并且可以向客户机提供网页浏览、数据库查询等服务的设备。而客户机则与之相反,它通过客户端软件(如浏览器)从服务器上获得网页浏览、软件下载等服务。简单地讲服务器就是服务提供者,而客户机则是服务获得者。
静态网页
在网站设计中,静态网页是网站建设的基础,纯粹 HTML 格式的网页通常被称为“静态网页”,静态网页是标准的 HTML 文件,它的文件扩展名是 .htm、.html,可以包含文本、图像、声音、FLASH 动画、客户端脚本和 ActiveX 控件等。
静态网页是相对于动态网页而言,是指没有后台数据库、不含程序和不可交互的网页。静态网页相对更新起来比较麻烦,适用于一般更新较少的展示型网站。
容易误解的是,静态网页并不是静止不动的,它也可以出现各种动态的效果,如 GIF 动画、FLASH、滚动字幕等。
静态网页服务的实现首先需要客户机通过浏览器向服务器发出请求,然后服务器接受请求并根据请求从服务器端的网页中找到对应的页面,最后返回给客户机浏览器。这个过程中所发送的页面都是事先编辑好的,它并不能自动生成。
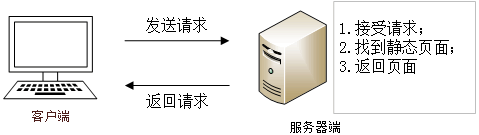
静态网页有以下特点:
- 静态网页不能自动更新,若要对静态页面进行更新,就要重新编写 HTML 源文件,然后再上传。因此静态网页的制作和维护工作量相当大。
- 静态网页的内容不随浏览用户、浏览时间等条件的变化而变化。无论何人、何时、何地浏览网页,它的内容都是一成不变的(不包括使用 JavaScript 实现的一些简单特效)。
- 静态网页一经发布,无论浏览者浏览与否,它都是真实存在的一个文件,都对应一个 URL(文件在网上的地址)。
- 用静态网页实现人机交互有相当大的局限性。由于不能动态生成页面,所以用静态网页来实现人机交互是很困难的,在功能上有很大限制。
动态页面
动态网页是基本的 HTML 语法规范与 PHP、Java、Python等程序语言、数据库等多种技术的融合,以期实现对网站内容和风格的高效、动态、交互式的管理。因此,可以理解为凡是结合了 HTML 以外的高级程序设计语言和数据库技术进行的网页编程技术生成的网页都是动态网页。
也就是说,动态网页相对于静态网页来说,页面代码虽然没有变,但是显示的内容却是可以随着时间、环境或者数据库操作的结果而发生改变的。
动态网页与网页上的各种动画、滚动字幕等视觉上的动态效果没有直接关系,动态网页也可以是纯文字内容的,也可以包含各种动画的内容,这些只是网页具体内容的表现形式,无论网页是否具有动态效果,只要是采用了动态网站技术(如 PHP、JSP 等)生成的网页都可以称为动态网页。
与静态网页相比,动态网页有以下特点:
- 动态网页在服务器端运行,客户机上看到的只是它的返回结果,不可能看到它的源文件。而静态网页则只能通过服务器把网页文件原封不动地传给客户机,本身不进行任何处理。
- 不同的人、不同时间、不同地点浏览同一个动态网页,根据代码处理结果不同,会返回不同的内容。
- 动态网页只有经客户浏览时才会返回一个完整的网页,而其本身并不是一个独立存在于服务器的网页文件。
- 与静态网页相比,动态网页更容易实现人机交互。与数据库相联系,能实现更为强大的功能。
- 由动态网页构建的网站维护起来比由静态网页构建的网站容易,只需要更新调用的数据(如数据库内容)即可。
与静态网页的实现方法不同,动态网页服务的实现首先需要客户机向服务器发送请求,然后服务器根据用户请求把动态网页内部的代码先在服务器上进行相应的处理,最后服务器把生成的结果发送给客户机,如下图所示:

动态网页与传统网页的区别
1) 更新和维护
静态网页内容一经发布到网站服务器上,无论是否有用户访问,这些网页内容都是保存在网站服务器上的。如果要修改网页的内容,就必须修改其源文件,然后重新上传到服务器上。静态网页没有数据库的支持,当网站信息量很大的时候网页的制作和维护都很困难。
动态网页可以根据不同的用户请求,时间或者环境的需求动态的生成不同的网页内容,并且动态网页一般以数据库技术为基础,可以大大降低网站维护的工作量。
2) 交互性
静态网页由于很多内容都是固定的,在功能方面有很大的限制,所以交互性较差。
动态网页则可以实现更多的功能,如用户的登录、注册、查询等。
3) 响应速度
静态网页内容相对固定,容易被搜索引擎检索,且不需要连接数据库,因此响应速度较快。
动态网页实际上并不是独立存在于服务器上的网页文件,只有当用户请求时服务器才返回一个完整的网页,其中涉及到数据的连接访问和查询等一系列过程,所以响应速度相对较慢。
伪静态
伪静态是相对真实静态来讲的,真实静态会生成一个html或htm后缀的文件,访客能够访问到真实存在的静态页面,而伪静态则没有生成实体静态页面文件,而仅仅是以.html一类的静态页面形式,但其实是用PHP程序动态脚本来处理的,这就是伪静态。
3.1.1HTTP请求
所有HTTP消息(请求与响应)中都包含一个或几个单行显示的消息头(header),然后是一个强制空白行,最后是消息主体(可选)。以下是一个典型的HTTP请求:
1 |
|
每个HTTP请求的第一行都由3个以空格间隔的项目组成.
GET:一个说明 HTTP 方法的动词。最常用的方法为GET.它的主要作用是从 Web 服务器获取一个资源。GET 请求并没有消息主体,因此在消息头后的空白行中没有其他数据。所请求的 URL,该URL 通常由所请求的资源名称,以及一个包含客户端向该资源提交的参数的可选查询字符串组成。在该URL中,查询字符串以?字符标识,上面的示例中有一个名为uid、值为129的参数。使用的HTTP版本,因特网上常用的HTTP版本为1.0和1.1,多数浏览器默认使用1.1版本,这两个版本的规范之间存在一些差异:然而,当攻击 Web 应用程序时,渗透测试员 可能遇到的唯一差异是 1.1 版本必须使用Host 请求头
Accept:浏览器支持的 MIME类型分别是 text/html、applicaticn/zhtml+xml、application/xml和 */*,优先顺序是它们从左到右的排列顺序。
详解:
Accept 表示浏览器支持的 MIME类型:
MIME 的英文全称是 Multipurpose Internet Mail Extensions (多功能 Internet 邮件扩充服务),它是一种多用途网际邮件扩充协议,在1992年最早应用于电子邮件系统,但后来也应用到 览器。
text/html, application/xhtml+xml, application/xml 都是MIME类型,也可以称为媒体类型和内容类型,斜杠前面的是type(类型),斜杠后面的是 subtype (子类型):type 指定大的范围, subtype 是 type 中范围更明确的类型,即大类中的小类。
Text: 用于标准化地表示的文本信息,文本消息可以是多种字符集和或者多种格式的:
text/html表示html 文档:
Application: 用于传输应用程序数据或者二进制数据,
application/xhtml+xml 表示 xhtml文档:
application/xml表示xml文档。
Referer:
Referer 消息头用于表示发出请求的原始URL(例如,因为用户单击页面上的一个链接)。请注意,在最初的HTTP规范中,这个消息头存在拼写错误,并且这个错误一直保留了下来。
Accept-Language 浏览器支持的语言分别是中文和简体中文,优先支持简体中文。
Accept-Language 表示浏览器所支持的语言类型,
zh-cn,表示简体中文:zh表示中文,
q是权重系数,范围 0 =<q <= 1, q值越大,请求越倾向于获得其“;”之前的类型表示的内容,若没有指定 q 值,则默认为1,若被赋值为0,则用于提醒服务器哪些是浏览器不接受的内容类型。
User-Agent:
User-Agent消息头提供与浏览器或其他生成请求的客户端软件有关的信息。请注意,由于历史原因,大多数浏览器中都包含Mozilla前缀。这是因为最初占支配地位的Netscape浏览器使用了User-Agent字符串,而其他浏览器也希望让Web站点相信它们与这种标准兼容。与计算领域历史上的许多怪异现象一样,这种现象变得很普遍,即使当前版本的InternetEplorer也保留了这一做法,示例的请求即由InternetExplorer提出。
Host:
Host消息头用于指定出现在被访问的完整URL中的主机名称。如果几个Web站点以相同的一台服务器为主机就需要使用Host消息头,因为请求第一行中的URL内通常并不包含主机名称
Accept-Encoding:
Accept-Encoding浏览器支持的压缩编码是gzin和deflate
Cookie:
Cookie消息头用于提交服务器向客户端发布的其他参数(请阅本章后续内容了解更多详情)。
Connection:
Connection表示持久的客户端与服务连接。
X-Forwarded-For:
X-Forwarded-For是用来识别通过HTTP代理或负载均衡方式连接到Web服务器的客户端最原始的P地址的HTTP请求头字段。
 wechat
wechat alipay
alipay


